The Real Scarcity
The AI race narrative has centered on three resources: GPUs, electricity, and talent. All three will keep growing. The one thing that gets thinner the more you mine it is data – specifically, data produced during the most cognitively demanding moments of human work.
I have been following the LLM industry since 2022, first as a VC investor and now as a researcher at Shanghai Innovation Institute building data-driven systems. What I want to work through in this essay is a single question: what game are the biggest labs actually playing with their data strategies?
These observations are first-principles reasoning from the outside. They are meant to clarify my own thinking, not to claim certainty about any company’s internal motives.
The Formula: Intelligence Density
I find it useful to decompose AI capability into a rough but workable formula:
AI Capability = Sum(Data x Intelligence Density) x Extraction Ability
Three factors. Data volume – the sheer amount a model can see. Intelligence density – how much concentrated human reasoning is embedded in that data. Extraction ability – how efficiently the model converts data into capability (architecture, training recipes, RLHF).
By 2026, extraction ability has converged more than most people realize. Transformer plus post-training is essentially public knowledge. What creates a 10x gap is the summation term – data volume multiplied by intelligence density. Volume is running out. What remains decisive is density.
A million low-density clickstreams cannot replace ten thousand high-density decision traces.

Figure from the original Chinese version.
Three Stages of the Data Race
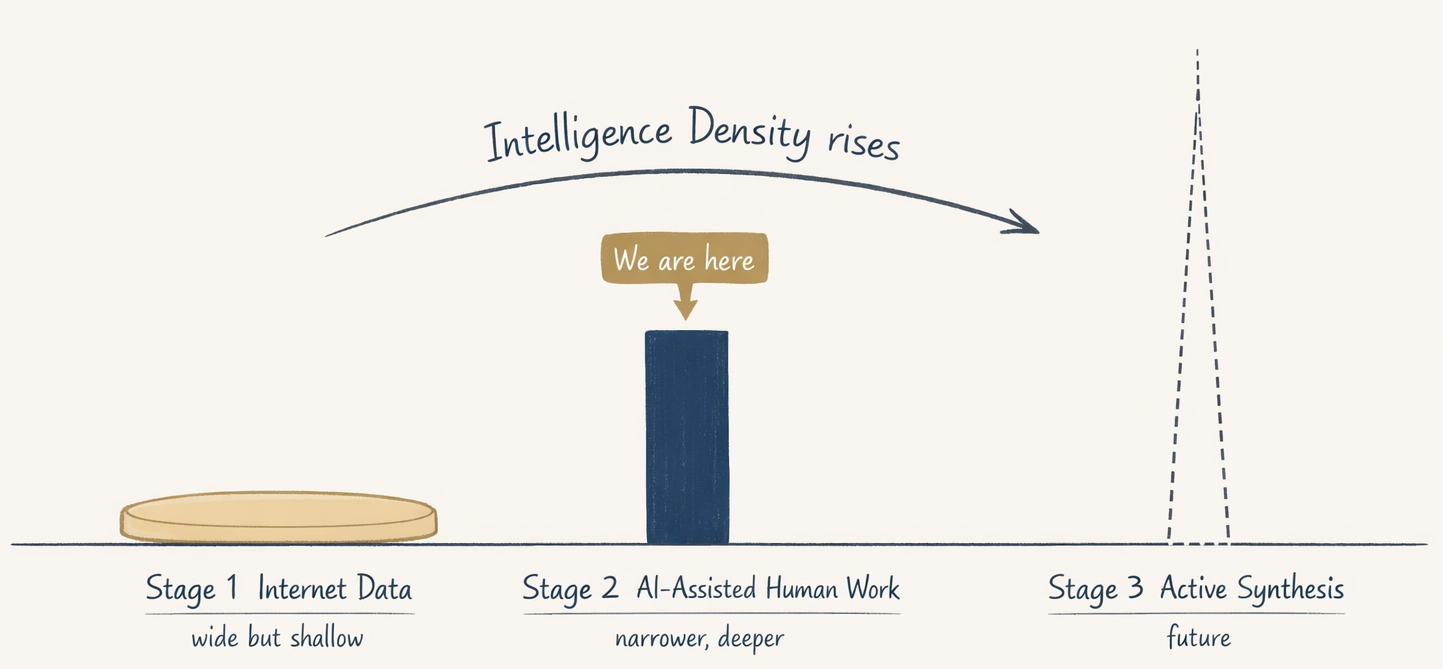
Figure from the original Chinese version.
The AI data supply over the past few years breaks into three stages, each with diminishing returns that force the transition to the next.
Stage 1: Internet data. The GPT-3 to GPT-4 era. Crawl the web, read every book, scrape all of GitHub. Enormous breadth, low density. This dividend was largely exhausted by 2024 – the stock of high-quality human-generated text on the open internet is finite.
Stage 2: AI-assisted human work. The current stage. Give a capable developer Claude Code, Cursor, or Codex. Every thought process, trade-off, revision, and acceptance decision they make while using the tool becomes a high-density sample of “how humans think through real problems.” The data density of this stage is one to two orders of magnitude higher than Stage 1.
Stage 3: AI observes time and distills experience. Still future-tense. Models follow real-world processes, autonomously summarize what works and what does not. The “world model” research direction is moving toward this.
The competition today is a fight for Stage 2 dominance. Labs are not competing for user hours – they are competing for the most cognitively expensive hours of the smartest users.
How Anthropic and OpenAI Diverge
Once you see the Stage 2 logic, Anthropic’s recent moves become coherent.
Subscriptions as data-for-discount. Claude Max at $200/month gives heavy users API-equivalent value worth thousands of dollars. One developer reported consuming roughly 10 billion tokens over eight months on Max – equivalent to approximately $15,000 in API costs, for $800 in subscription fees. The common explanation is that Anthropic is subsidizing growth. A more precise reading: under Anthropic’s default policy, subscription user data may be used for model improvement; API user data may not. The price gap is what Anthropic is willing to pay for your data. The more valuable your data, the deeper the discount.
Filtering for density. In April 2026, Anthropic blocked third-party tools like OpenClaw from accessing Claude through subscription OAuth. OpenClaw is not a coding assistant – it is a self-hosted gateway connecting Claude to WhatsApp, Slack, Telegram, and dozens of other messaging surfaces. The tasks flowing through it are simple, repetitive, and low-density. Under the data-for-discount framework, the logic is clear: the subscription discount exists because high-density developer workflows generate training value. OpenClaw routed low-density tasks through a channel designed for high-density data. The discount no longer made sense.
OpenAI read the same logic. In March 2026, they released an official Codex plugin that runs inside Claude Code – a pragmatic move. Claude Code already occupies the most valuable coding workflow. Rather than competing for the entrypoint, OpenAI embedded itself within it. The plugin provides code review (a second perspective on Claude’s output), adversarial review (challenging design decisions), and task handoff (rescuing tasks Claude gets stuck on). For developers, it is utility. For OpenAI, it is data – Claude’s code, Claude’s blind spots, and Claude’s failure modes all flow to OpenAI’s side.
The second-order effect is notable: developers who can productively use both Claude Code and the Codex plugin are a self-selected group whose interaction density far exceeds the average web user. Both Anthropic and OpenAI are mining the same vein – the judgment of the world’s best developers on real engineering problems.
The Hidden Filter: Why Most Labs Stall at Stage 2
Not every lab can run this playbook. The data-for-discount model requires two things: a product that occupies high-density workflows, and the scale to absorb the subsidy cost.
Labs without both are stuck in a synthetic data loop. They train on outputs from frontier models – a form of distillation that is efficient and cheap, but whose ceiling is capped by the distillation source. This is not a criticism; it is a rational response to constraints. When the cost of subsidizing your own users exceeds the training value of their data, buying distilled data from frontier model outputs is the better economic choice.
But from an industry perspective, the consequence is structural: labs in this position are locked into a chase-and-distill trajectory. Their capability ceiling is determined by the labs they distill from, and they generate little unique high-density data of their own.
The distinction that matters long-term is not who distills and who does not – in a world where models train on text that already contains traces of other models, the boundary is blurry. The question is:
Beyond other people’s data, do you have a source of new data that only you can produce?
That is the line between long-term leaders and perpetual chasers.
The Value Loop and What Comes Next
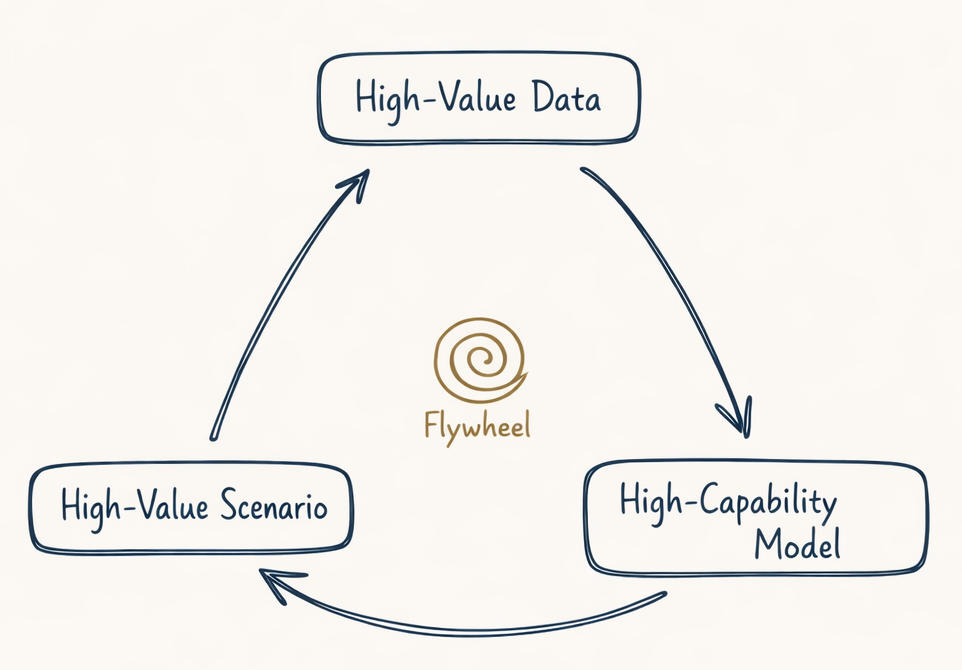
Figure from the original Chinese version.
If distillation is not a long-term strategy and user subsidies do not pencil out, what does? The path I keep returning to is building closed loops around high-value scenarios:
High-value data → high-capability model → high-value scenarios → higher-value data
Every arrow in this loop costs real resources. You need domain experts willing to invest their most cognitively demanding hours. You need models that are not just benchmark-competitive but demonstrably more reliable than any single expert in a specific domain. You need product forms that generate high-density feedback natively, not through post-hoc labeling.
The moat is not any single dataset. It is the flywheel – better models produce better annotation tools, which produce richer data, which produce better models. The compounding is the defense.
Recent developments suggest the frontier labs are already moving this direction. Anthropic’s Mythos Preview, delivered exclusively to a closed network of infrastructure partners rather than the public API, signals a potential shift from selling tokens to selling capability directly. When the strongest models stop being publicly accessible, the distillation path closes, and the only viable strategy is building your own data loop.
The next few years will not be decided by who has the highest benchmark scores. They will be decided by who reaches deepest into the most valuable human decision-making processes – and who builds the tightest loop between those processes and their models.
This essay is adapted from a Chinese-language article originally published on WeChat. Some examples and framing have been adjusted for an international audience.